
Three things that look unrelated: a German appellate court drowning in AI-generated complaints, Korean memory chip prices up over 500% from a year ago in some categories, and a code-review queue inside our own AI startup where review has become the main bottleneck in our engineering work. They are different shapes of the same problem. This essay is a framework for thinking about bottlenecks created by rapid AI progress. Where do they form? Why do they bind? How do we spot the next one before it binds?
Eine deutsche Übersetzung ist hier verfügbar.
1. Two Scenes
Scene A: A Press Conference in Essen
At its April 2026 annual press conference, the appellate court overseeing Germany's social-welfare cases in the state of North Rhine-Westphalia reported 7,615 emergency proceedings filed across its eight regional trial courts in 2025, a 55% jump in a single year. Standard cases now wait 15.6 months.[1]
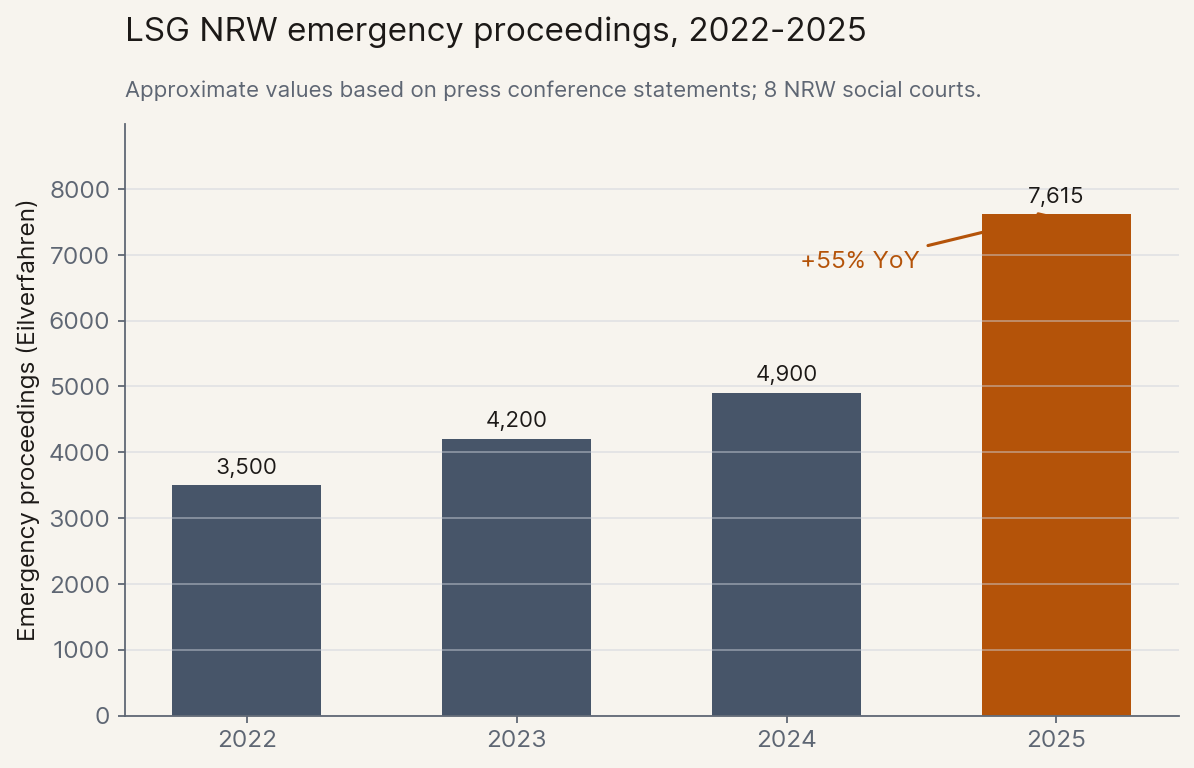
The court leadership named the cause: AI-generated complaints. The court president described the filings as "often very long, [containing] a multitude of often non-targeted motions and references to case law that sometimes does not exist." And this is just the first wave: today's filings come from non-experts using ChatGPT one prompt at a time, before agentic tools have meaningfully reached the broader public. Judges are being buried by text that costs almost nothing to produce but still has to be read line by line, and the curve has barely begun.
Scene B: A Monday Morning in Bremen
Inside our own company, a smaller version of the same story. ellamind builds and evaluates enterprise AI agents, mostly in Germany. After Anthropic shipped Claude Opus 4.5 in late 2025, our engineers' raw output stepped up sharply. Within weeks, the team had over 50 finished pull requests waiting to be merged, roughly five times what we normally carry in the queue, and not enough humans to review them.
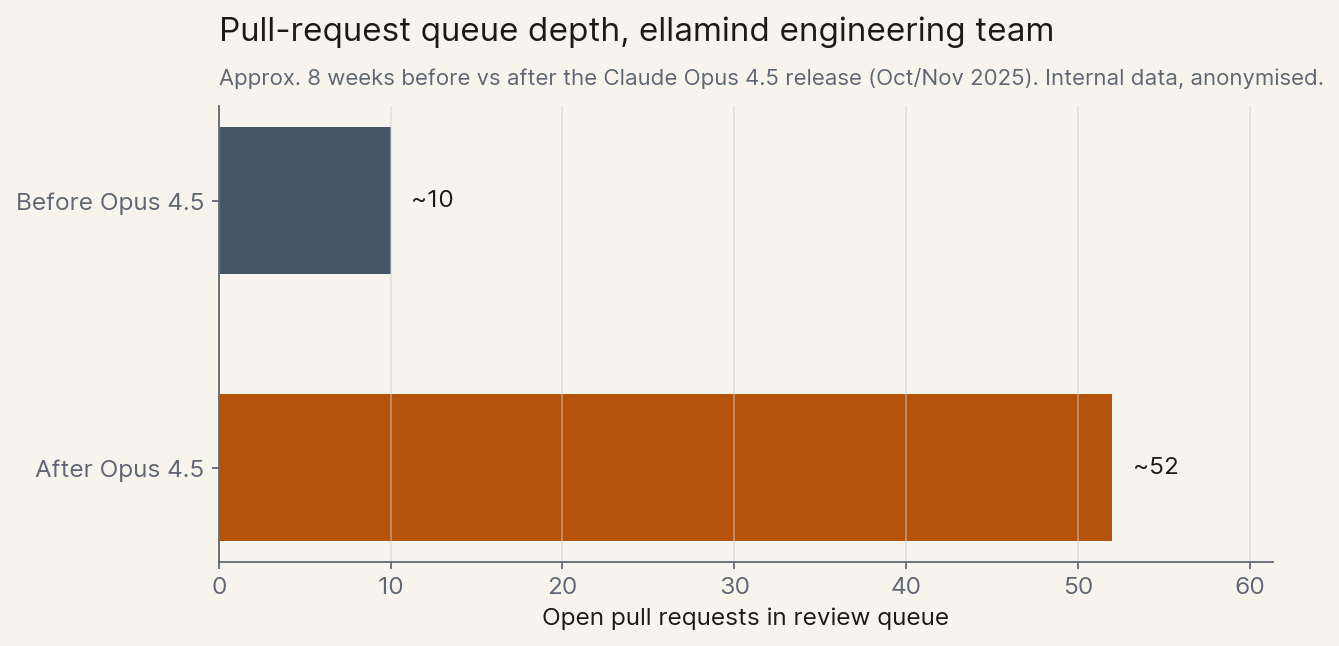
Reviewing a non-trivial pull request does not parallelize. You have to load the change into your head, walk it against the system you already understand, judge whether the test coverage is real or theatre, and accept liability for what ships. None of that compresses when the writing side gets faster. Our reviewers are good and few; the depth of review is contractually fixed; the queue grew.
The constraint did not vanish when the AI got better at writing code, it moved one step. The bottleneck went from "writing code" to "trusting code", and the people on the trusting side started to feel it.
The Same Shape
A German social court judge in Essen and a code reviewer in Bremen sit on the same side of the same problem. A new tool has dropped the cost of producing one kind of document close to zero, while the cost of reading, evaluating, and signing off on those documents has barely moved. The people on the second side now sit underneath a queue that did not exist eighteen months ago, growing faster than they can hire.
The faster AI gets at producing, the more pain flows to whoever has to check. That pattern is everywhere once you look for it, and it is the natural sequel to the picture I drew in A Country Full of Geniuses two months ago: when the geniuses arrive in the datacenter, the binding constraints in the rest of the economy are what we have to think about next.
2. The Slowest Clock
It helps to put a frame around the shape from Section 1, because there is already a dominant frame in circulation and it points the other way.
The most influential image of what powerful AI does is Dario Amodei's "compressed 21st century" from Machines of Loving Grace (Oct 2024). Intelligence is initially heavily bottlenecked by the other factors of production, but over time intelligence itself routes around those factors. Compute, capital, talent, lab space, regulation; in the long run, a sufficiently capable system finds a way through each of them. A hundred years of biological progress in five to ten. A country full of geniuses in a datacenter.
Read that frame carefully and the load-bearing words are "over time." Fast takeoff is exactly the case where time is not there.[2] If the model side doubles every four months and the rest of the world does not, the routing-around argument runs out of runway before it runs out of intelligence.
Even Amodei concedes this when pressed. To Dwarkesh Patel in February 2026, he put it plainly: "I can't buy $1 trillion a year of compute in 2027."[3] In the same interview he pointed to enterprise change management, clinical trials, and the life cycle of legislation. Each is a clock that intelligence cannot speed up by getting smarter.[4]
Engineers will recognize the underlying structure: Amdahl's law, applied to the economy. If you speed up one part of a process and another part stays the same, the maximum speedup of the whole is set by the slow part, not the fast one. Make the AI side 100x faster at the parallelizable work, and if 10% of the process remains serial and human, the maximum speedup of the whole process is roughly 9x. No matter how good the model gets, the slow 10% sets the ceiling.
That is the working principle of this essay, and I want to state it once, plainly, so it can do its work in the rest of the piece. The slowest clock governs the system. Every bottleneck I discuss is a clock running at human, institutional, or physical speed. The fastest clock is the model. The system can only run as fast as its slowest clock.
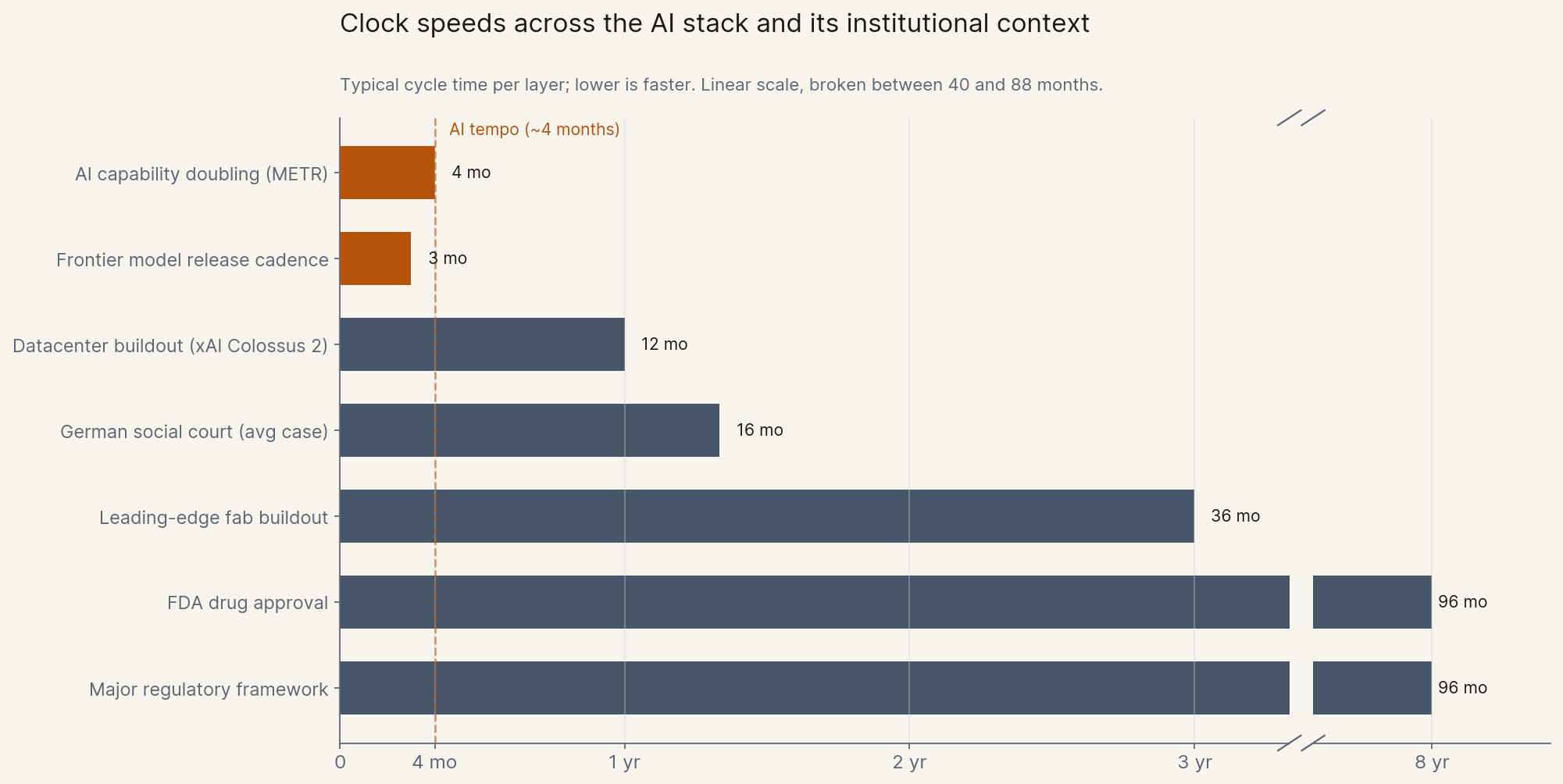
The slowest clock changes from layer to layer, and the rest of this essay walks three of them: silicon, the human in the loop, and the institutional clocks above both. Start with the first and most concrete.
3. The Supply-Shortage Era
Silicon is the cleanest case for the slowest-clock principle and the first layer of the analysis, because every clock in the stack is measured in wafers per month and the slowest one is visible on a public price chart.
The frame has flipped fast. In early 2025 the dominant question about AI was "is demand real?" By April 2026 Derek Thompson could write that we have moved "from a period of demand scarcity (not enough customers) to supply scarcity (not enough compute)."[5] Markets have stopped pricing whether AI gets used. They are pricing who owns the capacity.
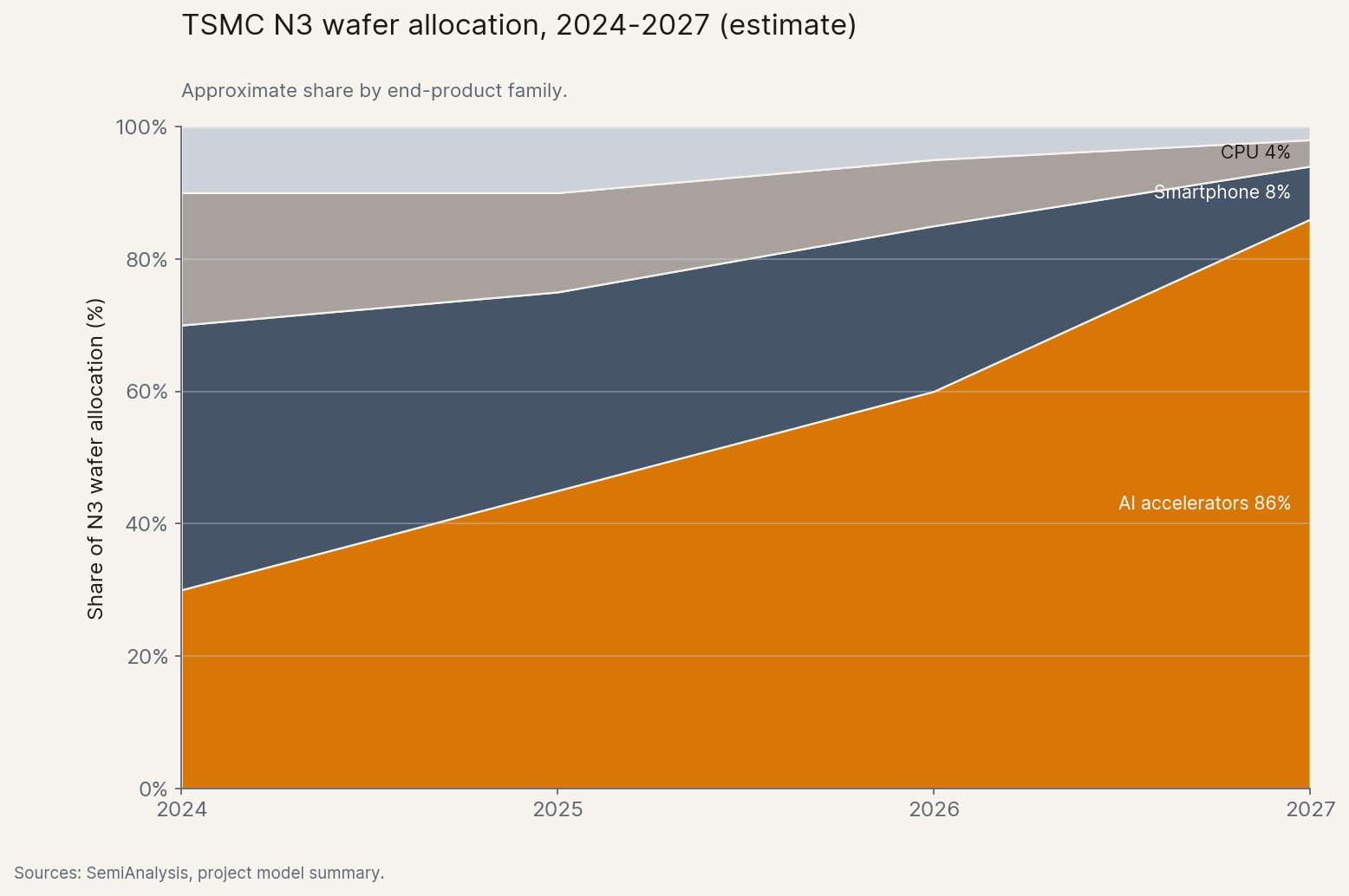
The simplest layer is the chip itself. Every leading AI accelerator in 2026 is fabricated on the same advanced manufacturing node at TSMC, and AI alone is projected to claim the majority of that node's output by 2027 — pushing smartphones and ordinary CPUs aside.[6]
Memory and packaging show the same pattern in sharper form. The high-bandwidth memory that every AI accelerator needs has eaten an outsized share of total DRAM capacity, and Korean export prices for memory have lifted near-vertically — some categories now trade at several times last year's price.[7] The advanced packaging that fuses logic and memory is the single most rationed item in the stack. And the geopolitical chokepoint is structural: Taiwan for logic, Korea for memory, two countries deep.
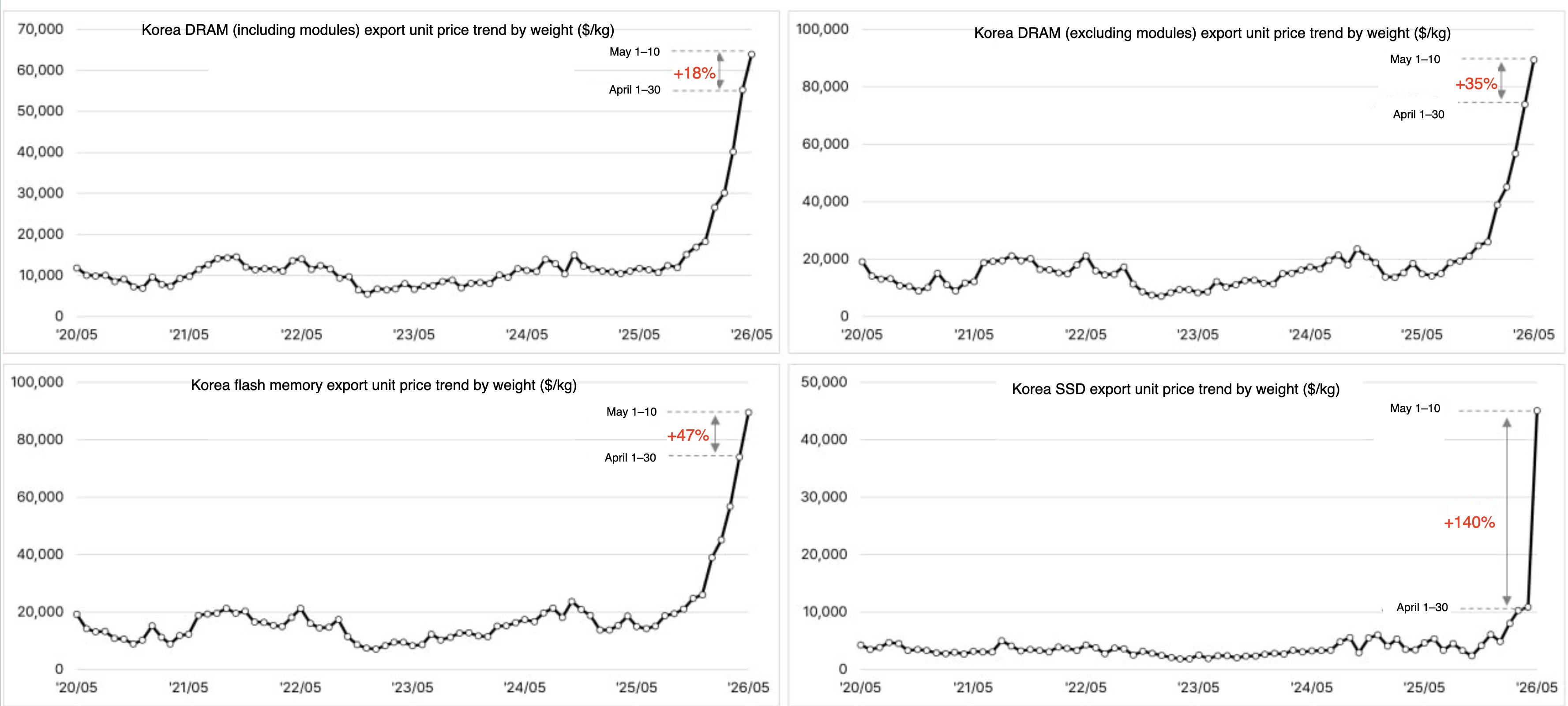
A new wrinkle has appeared in 2026: agents need their own compute. Each autonomous agent loop is, in effect, a small server doing CPU-side orchestration around model calls, and the CPU sleeve of the supply chain has woken up. AMD is up 343% on the year, Intel up 483%. Wall Street has rotated from "Nvidia or nothing" to "anyone with capacity."[8]
The demand side has already started buying optionality rather than capacity. In April 2026, two large AWS customers asked to buy all of AWS's 2026 capacity for Graviton CPUs. AWS declined. Trainium (AWS's in-house chip family for AI training and inference, the alternative to renting NVIDIA capacity) shows the same pattern: Trainium2 is largely sold out, Trainium3 nearly fully subscribed, and Trainium4 (eighteen months out) already has significant pre-bookings. Microsoft's CFO Amy Hood told the Q1 2026 earnings call that capacity shortages would extend through the fiscal year.[9]
When intelligence becomes abundant, scarcity rents accumulate at every layer that cannot scale linearly. Public markets have priced this faster than public discourse, and the surprises sit well below the obvious anchors of NVDA, TSM, and ASML.
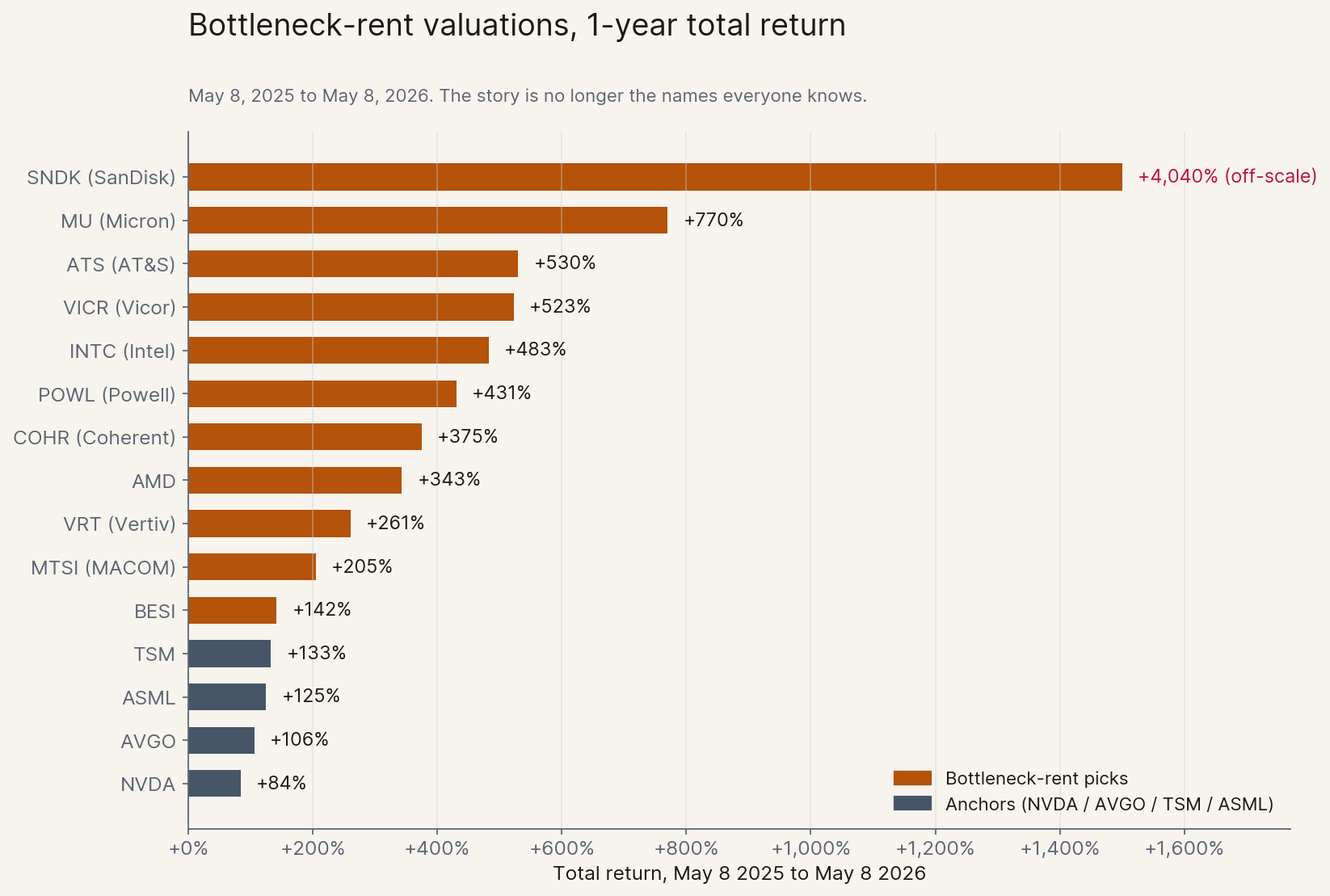
The bottleneck rent is the most consequential capital reallocation of this cycle, and it sits with whoever owns the constraint that intelligence cannot route around in time.
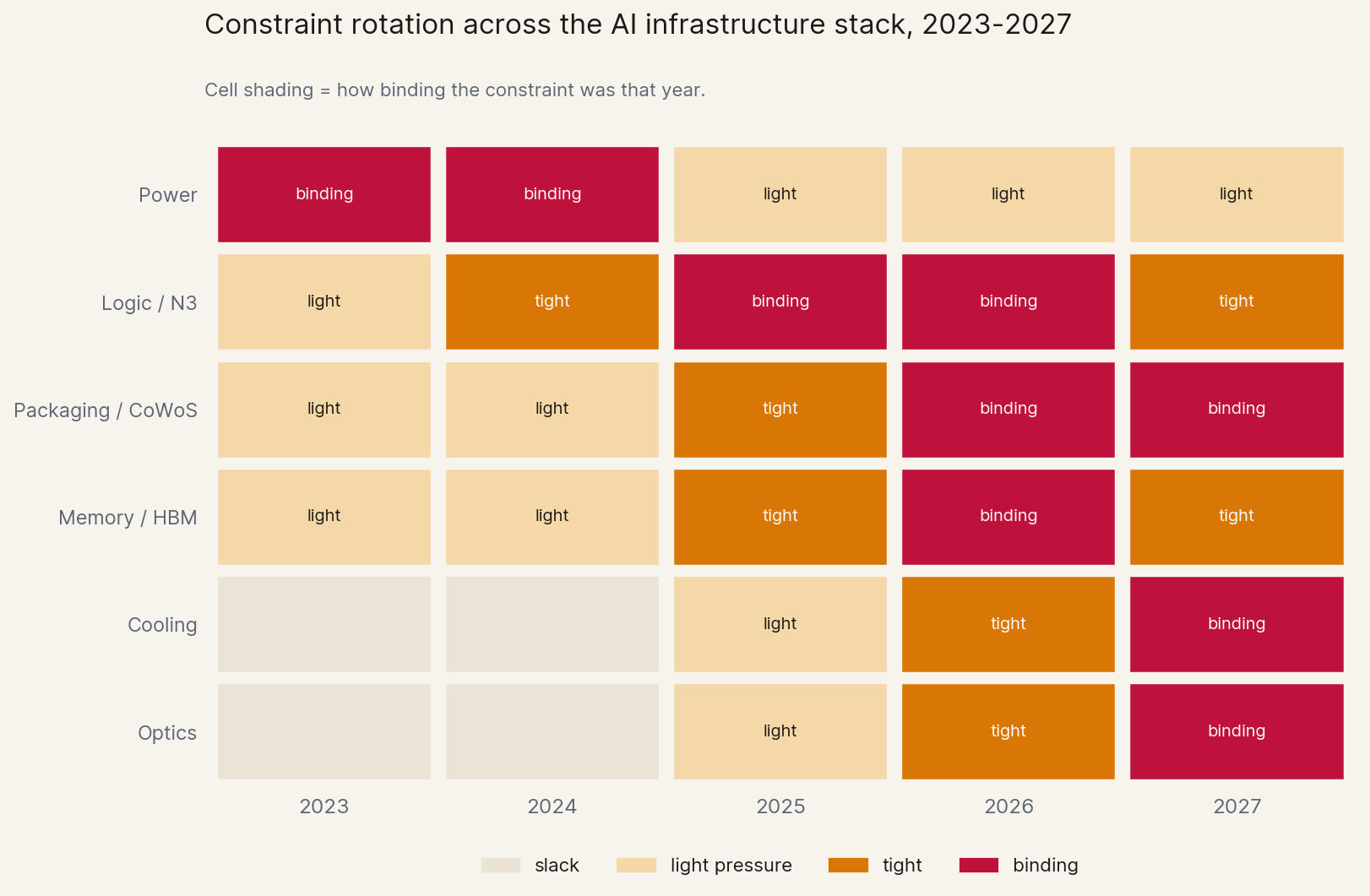
And it keeps rotating: yesterday's binding constraint was power, today's is logic and packaging, tomorrow's will likely be something else entirely. The rent moves with the bottleneck, and whoever sees the next rotation first captures it.
4. The Interface Tax
Silicon is priced in a public market. The second layer, the cost of being the human in the loop, is priced indirectly, through queues and review hours and signatures. No less real, just harder to see on a chart.
The cleanest formalisation comes from a recent paper by Christian Catalini and co-authors at MIT, Some Simple Economics of AGI (Feb 2026). The argument fits on an envelope. Two cost curves matter: the cost to automate a task (cA) which falls roughly exponentially as models improve, and the cost to verify the result (cH) which is biologically capped by human time, attention, and embodied judgment. cA crashes; cH barely moves. Catalini calls the widening space between them the Measurability Gap, and his framing of the consequence is the thesis of this section: "the binding constraint on growth is no longer intelligence. It is human verification bandwidth."
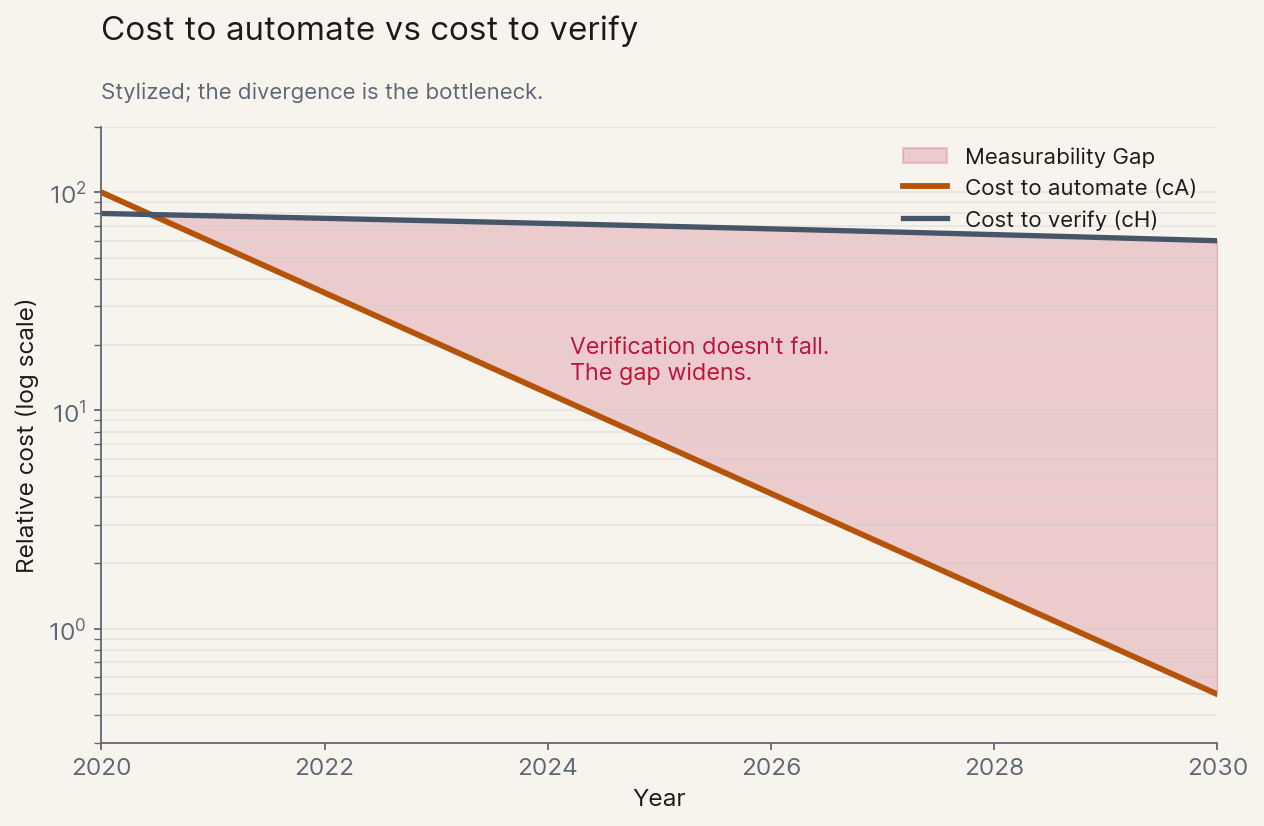
The most underreported number of 2026 lives in OpenAI's GDPval study. Naively, GPT-5 completes the benchmark's expert tasks roughly 90x faster than a human professional. Once you account for the human time still required to review the output ("try once, fix it"), GPT-5 ends up only about 1.18x cheaper than the human working alone. Almost all of the headline speed evaporates at the verification step.[10]
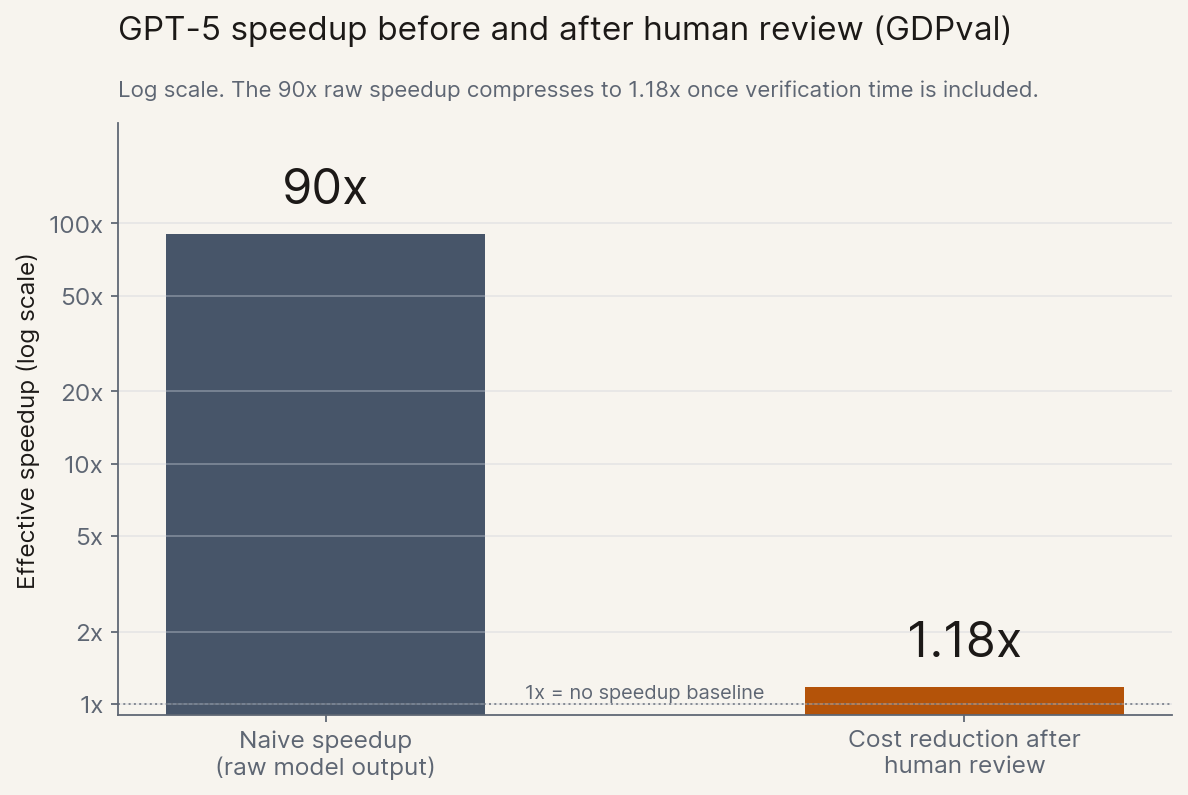
This is the same shape as the ellamind code review story from Section 1. Code review is a verification gate that does not scale automatically when the AI side scales. The model writes faster; the reviewer's working memory does not. Once you see the pattern, you see it everywhere a regulated process touches an AI output.

The pattern shows up wherever a regulated process terminates in a human signature. In banking, the four-eyes principle mandates two licensed humans on every critical action; equivalent rules bind pharma manufacturing, energy trading, public procurement, and parts of public-sector decision-making across most developed economies. Pharma runs batch records, lab notebooks, and clinical-trial source-data verification through human signatures under FDA Part 11 and EU GMP. Whether it is a credit decision, a clinical batch release, a board-approved trade, a contract review, a patent prosecution, or a deployed-model release, the gate is the same: signed off by a person who carries personal liability. ellamind's customers operate inside these gates, and our work is, in plain terms, building infrastructure for the verification side. Verification economics has gone from paper to product category.
Catalini gives this its sharpest name: the Trojan Horse externality. Unverified AI output consumes real resources downstream: filing fees, court time, reviewer attention, errors that propagate into real harm. The German social-courts story from Section 1 is the canonical instance, cheap to produce and expensive to absorb. The cost of generation sits with the producer; the cost of verification is socialised onto judges, regulators, and reviewers. Inside one company the cost shows up as a queue; one level up, the same dynamic decides whether an entire institution can keep pace with the technology in front of it.
5. The Institutional Clocks
The interface tax explains why individual reviewers and approvers are getting buried. The same arithmetic, one level higher, explains why the institutions they belong to are too. Take drug development as the cleanest case. Anthropic's own writing on the topic, picked up and sharpened by Tyler Cowen, gives the formulation almost too neatly: if AI increases the rate of pharma ideas by 10x, the relevant constraint becomes the rate of drug approval rather than the rate of drug discovery. The FDA pipeline does not move on a four-month doubling; Phase I to approval still runs roughly a decade. Most of the discoveries an accelerated discovery layer produces will queue. This is the deepest expression of the working frame: the slowest clock governs the system.
The same shape shows up in courts. The German social-court story from Section 1 is not a regional curiosity, it is the general case. AI lowers the marginal cost of producing legal text, complaints, briefs, appeals, toward zero. Courts do not scale: judges, hearing officers, and clerks are human-bandwidth-bound, and adding capacity requires legislation, training, and physical rooms. The result is queue length, which is its own kind of failure: justice delayed is justice denied. And remember, today's filings are still mostly the work of citizens running ChatGPT one prompt at a time. Agents capable of preparing dozens of complaints in a single session have not meaningfully reached the broader public yet. When they do, expect another order of magnitude of throughput on the producer side, against the same number of judges.
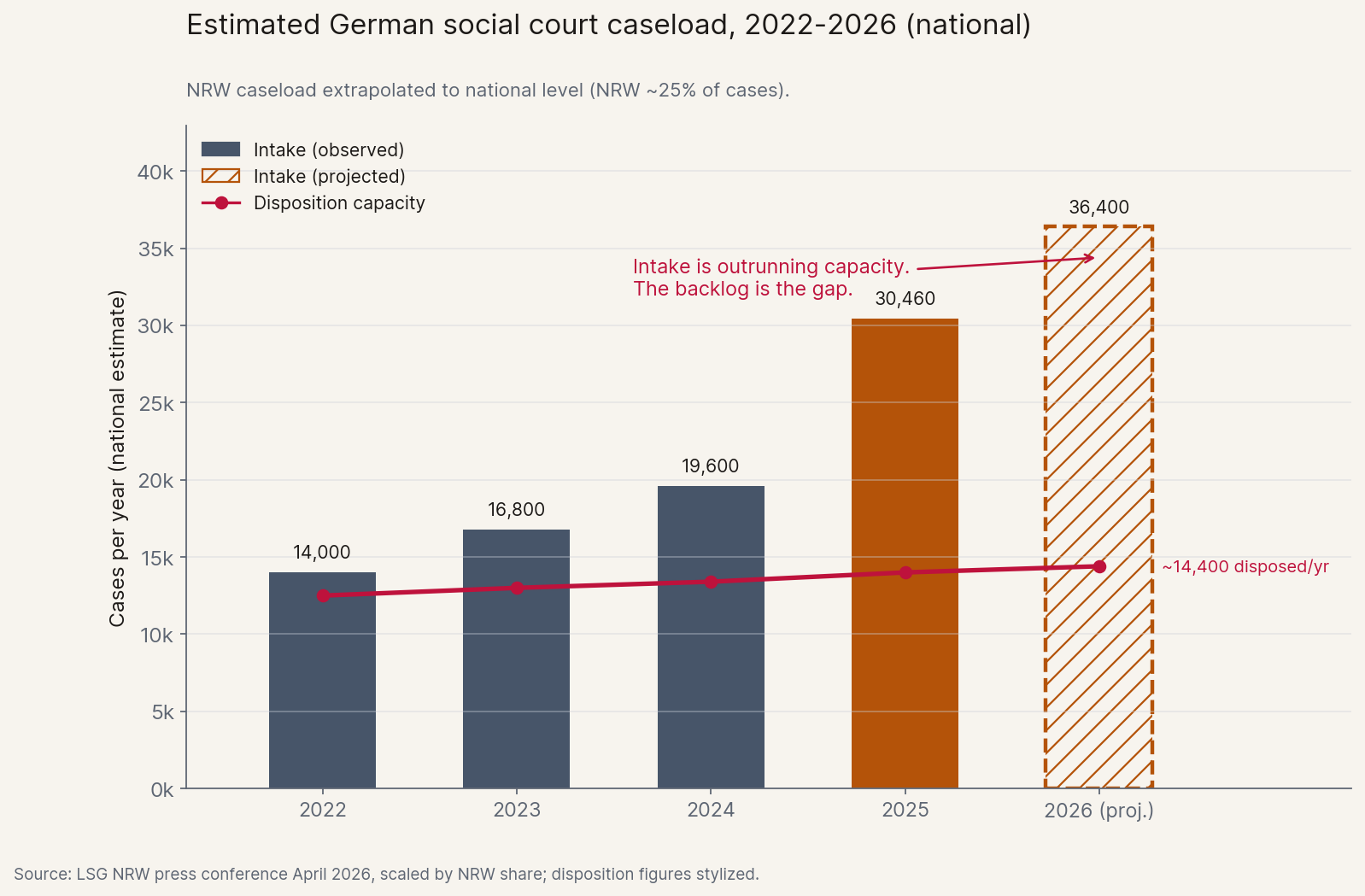
This is the same disease as the code-review collapse from Section 1, in a different organ. Code review is what happens when verification capacity inside one team falls behind generation. The court backlog is what happens when verification capacity inside one society does. The arithmetic is identical.
Regulatory and standards bodies sit in the same trap. EU AI Act enforcement is staged across 2025-2027; BaFin, Germany's financial supervisor, runs consultations on yearly cycles; the FDA and SEC operate on similar legislative timescales. The slow cycle is what these institutions are for; they are designed to be deliberate. But under a four-month capability doubling, deliberate is indistinguishable from absent. The design point produces a permanent regulatory lag, which in turn pushes activity into either grey markets or non-compliant deployment.
Add it together. Institutions are designed for the slowest, most deliberate human pace. AI does not slow down to match. So institutions either get faster, or they get bypassed, or they collapse under queue pressure.[11]
Worth being concrete about what those last two mean, because neither requires an institution to formally stop operating. Push the social-court wait to three years (a realistic destination if intake continues at +55% year-over-year against a hiring cycle measured in years) and the institution exists on paper while its function migrates to mediation, insurance, and informal channels. The same is true elsewhere: an FDA whose approval pipeline runs a decade is, for the operational window where it matters, not approving treatments at the rate of biological discovery; a regulator whose consultation cycles trail the technology by two years is, for that window, absent. Below some throughput floor, an adjudicative body stops adjudicating, and that is what collapse under queue pressure actually looks like. The choice between speeding up, being bypassed, and collapsing is now an active political question, and the cost of getting it wrong is that the institution stops doing what citizens, patients, and markets need it to do.
6. What This Means
Three layers, one shape. Now the practical question: what do you do with this lens?
6.1 Disruption Is Asymmetric
The standard "AI takes jobs" framing predicts pain inside AI-native workflows. Bottleneck thinking predicts pain at the interfaces. The doctor signing off on the radiology AI. The judge reading AI-generated complaints. The compliance officer reviewing AI-drafted contracts. The manager evaluating AI-written performance reports. The code reviewer trusting AI-written PRs. These roles intensify rather than vanish; the people in them feel overworked, not redundant. That is a different policy problem from the one most public debate is set up to solve.
Ethan Mollick has been making a related point: as he put it in The Shape of AI: Jaggedness, Bottlenecks and Salients (Dec 2025), AI capability advances along a jagged frontier, and when one bottleneck breaks, "everything behind it comes flooding through." The visible change is uneven precisely because of the bottleneck mechanic. The capability was already there. What moves is the constraint.
6.2 What This Means for Politics and Non-Tech People
Three concrete claims, framed for the reader who is not in tech:
First, regulatory speed and adaptability becomes a strategic national asset. A country with fast courts, smart and fast regulators, abundant fab capacity, and a reliable grid may capture AI value better than one with abundant talent alone. This inverts decades of policy intuition. Investment in administrative throughput, judicial capacity, permitting reform, and electrical grid capacity is now AI-economic policy, even when no one labels it that way. The German social-court story from Section 1, read in this light, is an industrial-policy story.
But there is a harder corollary, and it cuts especially close to home in Europe: institutions themselves have to adopt AI internally if they want to survive their own queues. The way out of the social-court backlog is not just hiring more clerks. It is having low-stakes, high-volume cases triaged or pre-decided by AI, with human judges focused on the harder ones. We do something analogous inside ellamind: smaller, low-risk pull requests are reviewed end-to-end by an automated reviewer, and humans only enter when the stakes or the change surface justify it. The guardrails matter enormously, the design has to fail safe, and the categories of "low-stakes" must be drawn carefully. But the alternative, keeping verification entirely human as the producer side scales 100x, is not a recoverable position. Institutions that do not build their own verification layer will lose the ability to govern the producers.
Second, political fights move from "AI safety" to "who gets the slot." Whoever owns a constrained layer collects the rent. FDA approval throughput, court time, TSMC N3 wafer capacity, electrical permits, construction labor. The next decade's political front lines are permitting reform, judicial budgets, regulatory headcount, and grid interconnect queues. These are technical-sounding fights with very large distributive consequences, and the AWS sold-out story from Section 3 is what they look like before they reach the public domain. They are AI fights even when no one calls them that.
Third, for non-tech people the question is not "will AI take my job?" but "am I the verifier in my workflow?" If yes (doctor, judge, manager, reviewer, compliance officer, certain teaching and operations roles), expect intensification, not redundancy. The role shifts toward judgment and accountability, exactly the verification economics from Section 4. Train for that. If you produce text, code, designs, analysis, and someone else signs off, expect commoditisation. The value flows to whoever takes responsibility for the output. The professions most under-discussed in current AI-and-jobs coverage are middle management and operations, which exist precisely because they are the verifier layer for everyone below them. They are about to become much more important and much harder.

6.3 Tools for Applying the Bottleneck Lens
A practical toolkit, deliberately small.
Tool 1: The three-question test. For any workflow, process, or sector you care about, ask:
- What does AI 10x here?
- What step does it not 10x?
- Is the un-10x'd step a human, an institution, or a physical resource?
The answer to question (3) tells you whether you are looking at an interface, institutional, or physical bottleneck. That, in turn, tells you how the disruption will feel and where the rent will accrue. The hospital and the chip fab give different answers; both are diagnostic.
Tool 2: The bottleneck rotation map. Bottlenecks move. Yesterday it was power, today it is TSMC N3 and CoWoS, tomorrow it might be grid interconnect, verifier headcount, or court calendars. The mistake is fixating on a single constraint and missing the rotation. Practical heuristic: by the time a bottleneck becomes consensus, the binding constraint may have already moved one layer downstream. The discipline applies to physical bottlenecks and equally to institutional ones. When the press finally writes about court backlogs, the binding constraint may have already moved to clerk training capacity.
Tool 3: Personal positioning. Invest in verification skills (judgment, taste, accountability, domain ownership) over execution skills (writing, coding, designing, basic analysis). The first set is bottleneck-side and appreciates. The second is the side AI compresses. This is a directional bet, not a recipe; the specific skills depend on the domain. But the direction is clear.
Closing
I have been in AI deployment for years now, at the frontier of what models can do day to day, and I am still surprised by the speed at which the producer side is improving. If the curve continues as Anthropic and OpenAI are now openly betting it will, with automated AI research arriving within roughly two years, the question that dominates the late-2020s shifts from whether the geniuses arrive in the datacenter to how well we manage the bottlenecks they slam into when they do, in the economy, in the courts, in the labs, and inside the companies and ministries trying to use them.
The slowest clock is rarely where the excitement is. It is where the patient work sits, where the next decade's quietest fortunes will be earned, and the loudest institutional failures avoided.